.
<span>Photo by <a href="https://unsplash.com/@goran_ivos?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Goran Ivos</a> on <a href="https://unsplash.com/s/photos/data-normalization?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a></span>
# **What is Normalized Data?**
Normalized data within statistics in most cases involves eliminating units of measurement from a dataset. As a result, this enables you to easily compare data with different scales and are measured from different sources.
# **Why is Normalized Data Important?**
When training a machine learning model, we aim to bring the data to a common scale and so the various features are less sensitive to each other. In this case, we can utilize data normalization as a method of transforming our data, which may be of different units or scales. This allows our model to train using features that could lead to more accurate predictions.
## Methods of Normalizing Data
### Simple Feature Scaling
---
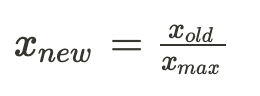
The simple feature scaling will normalize a value between -1 and 1 by divided by the max value in the dataset.
We can implement this in python:
```python
#importing pandas
import pandas as pd
#creating dataframe our data
df = pd.read.csv('example.csv')
#function which return return of simple eq
def norm(item):
return (item)/(item.abs().max())
#apply norm function to each item in dataframe
df = df.apply(norm)
df
```
We can implement this using scikit-learn:
```python
#importing maxabsscaler
from sklearn.preprocessing import MaxAbsScaler
#creating maxabsscaler object
norm = MaxAbsScaler()
#applying norm to dataframe
df_norm = pd.Dataframe(norm.fit_transform(df), columns=df.columns)
df_norm
```
### Min-Max
---
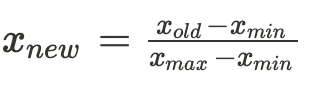
The min-max method will scale the feature to a fixed range between 0 and 1.
We can implement this in python:
```python
#function which return return of min-max eq
def norm(item):
return (item - item.min())/(item.max() - item.min())
#apply norm function to each item in dataframe
df = df.apply(norm)
df
```
We can implement this using scikit-learn:
```python
#importing minmaxscaler
from sklearn.preprocessing import MinMaxScaler
#creating minmaxscaler object
norm = MinMaxScaler()
#applying norm to dataframe
df_norm = pd.Dataframe(norm.fit_transform(df), columns=df.columns)
df_norm
```
### Z-Score
---
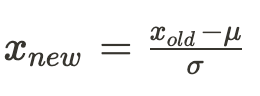
The Z-Score is the measure of standard deviations between the actual value and a predicted value. In order to calculate this value we must first know the mean value and the standard deviation.
We can implement this in python:
```python
#function which return return of z-score eq
def z_score(item):
return (item - item.mean())/(item.std())
#apply norm function to each item in dataframe
df = df.apply(z_score)
df
```
We can implement this using scikit-learn:
```python
#importing standardscaler
from sklearn.preprocessing import StandardScaler
#creating standardscaler object
norm = StandardScaler()
#applying norm to dataframe
df_norm = pd.Dataframe(norm.fit_transform(df), columns=df.columns)
df_norm
```
Normalizing data allows for transforming each item to a common scale. Implementing data normalization is simple as we have shown by also utilizing scikit-learn to easily normalize without using the equations.
Data Normalization in Python
When working on machine learning projects, you need to properly prepare the data before feeding it into a model. One method to perform on a dataset is normalization.

